Sōzu — the Open Source Reverse Proxy Built in Rust
Sōzu takes care of Web traffic for highly demanding infrastructures. It's implemented in Rust to provide the necessary Safety, offering rock solid infrastructures.
It's also your perfect solution if you need a Reverse proxy capable of thousands of new deployments a day.
GitHub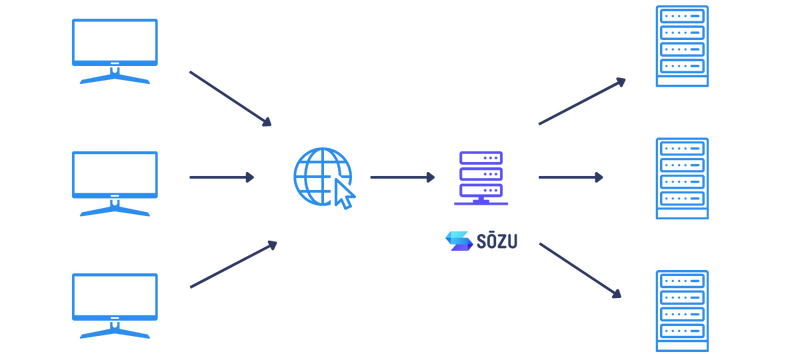
What’s Sōzu?
Sōzu is used by Cloud providers and PaaS provider to drive their moving Web infrastructure, adding new Apps and Customers every second. How do we reconcile a dynamic environment with availability guarantees? How can we get 'zero downtime' deployments for critical services?
- A TCP and HTTP reverse proxy built in Rust
- Dynamic: Handle configuration changes without reloads
- Designed to be always up even while upgrading itself!
Share Nothing Architecture
Each worker runs a single thread with an epoll based event loop
- No synchronization issue
- Workers open TCP Sockets with SO_REUSEPORT to listen on the same address
- All observability work is left to an external service for optimal performance and no bottleneck on traffic management

Never lose any connections!
Sōzu is designed to avoid loosing any connection. Also it handles configuration changes at runtime and updates its internal configuration without reload.
- Manage multiple update configuration changes per second, without losing connections
- Use main process/workers model to avoid losing connections even with binay upgrades!
Made for Control Planes
External tools interact with the main process through a unix socket, with a binary based protocol (ProtoBuf).
- Configuration is applied as atomic diff
- No full reload which is suitable for large configurations under load
Logging
The logger is designed to reduce allocations and string interpolations, using Rust’s formatting system. It can send logs on various backends: stdout, file, TCP, UDP, Unix sockets.
Metrics
Metrics work like the logger, accessible from anywhere with macros and TLS. We support two ‘drains’: one that sends the metrics on the networks with a statsd compatible protocol, and one aggregating metrics locally, to be queried through the configuration socket.
Load Balancing
For a given cluster, Sōzu keeps a list of backends to which the connection is redirected. Sōzu detects broken servers and redirects traffic only to healthy ones, with several available loadbalancing algorithms:
- Round Robin (default)
- Random
- Least_loaded
- Power of two algorithm
Stability & Safety
Sōzu works with fixed ressources and connections limits, to avoid common issues like OOM kills or increased latency with a high number of connections. It is written in Rust to provide safety from memory vulnerabilities, reliability through a lack of garbage collection, and performance with an optimized event loop.